Data Structure
ISM data structures come from these source types.
Manual
This type consists of field groups, and field groups are comprised by fields. This type data has master-detail hierarchy.
This type data structure is generated with this order.
· Field - create fields one by one.
· Field group - create field groups with fields.
· Master/Detail - Assemble master/detail with field groups.
DB
This is from table. There are two types of data structure generation.
· From table layout - ISM connects to the target database, retrieves table information, and choose a table.
· From user query - ISM executes the query and generate a data structure.
Excel
This type is from an excel file.
There are two types of data structure generation.
From template - the excel sheet follows ISM data structure template.
From header - the values of the first row of the excel sheet are the names of the fields.
XML
This type is from a sample xml content.
JSON
This type is from a sample json content.
WSDL
This type is from a WSDL.
Manual
This is the original type of data structure of ISM. This type of data structure consists of multiple (1..N) masters and multiple (0..N) details.
Master and detail are field groups. One master field group can have multiple (0..N) detail field groups.
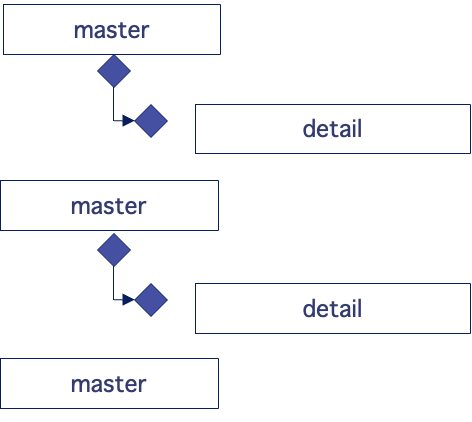
Detail field groups can be repeated.

The data above screenshot consists of one header part and repeated body part. This is the data structure of the data.

The header has 3 fields and body has 2 fields and repeatable. The repeat count, i.e., the record count is determined by the 3rd field of the header. The 3rd field of the header indicates repeat count is 5, and body part is repeated 5 times. If the repeat count is fixed, then no indicator is used.
This data has a record delimiter, and this record delimiter is used to separate master records and detail records in the master. If a record delimiter is set, then the same delimiter is used to separate the detail records.
These are the steps to create a new data structure.
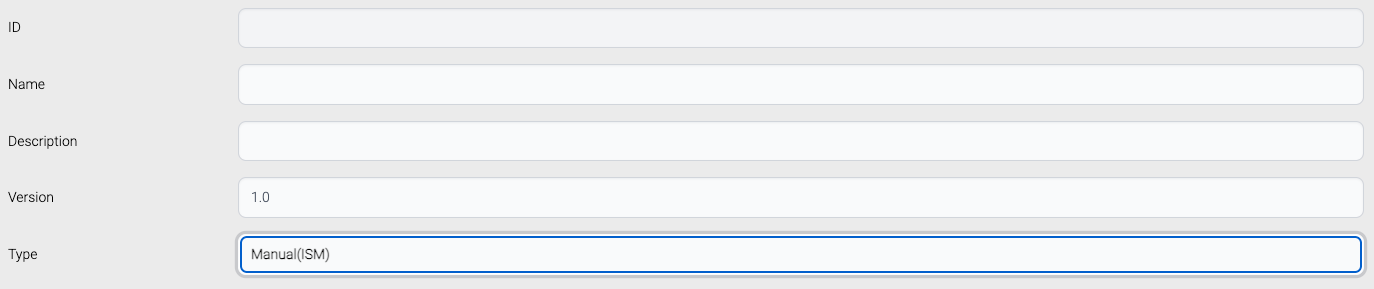
· Choose type - Manual(ISM)
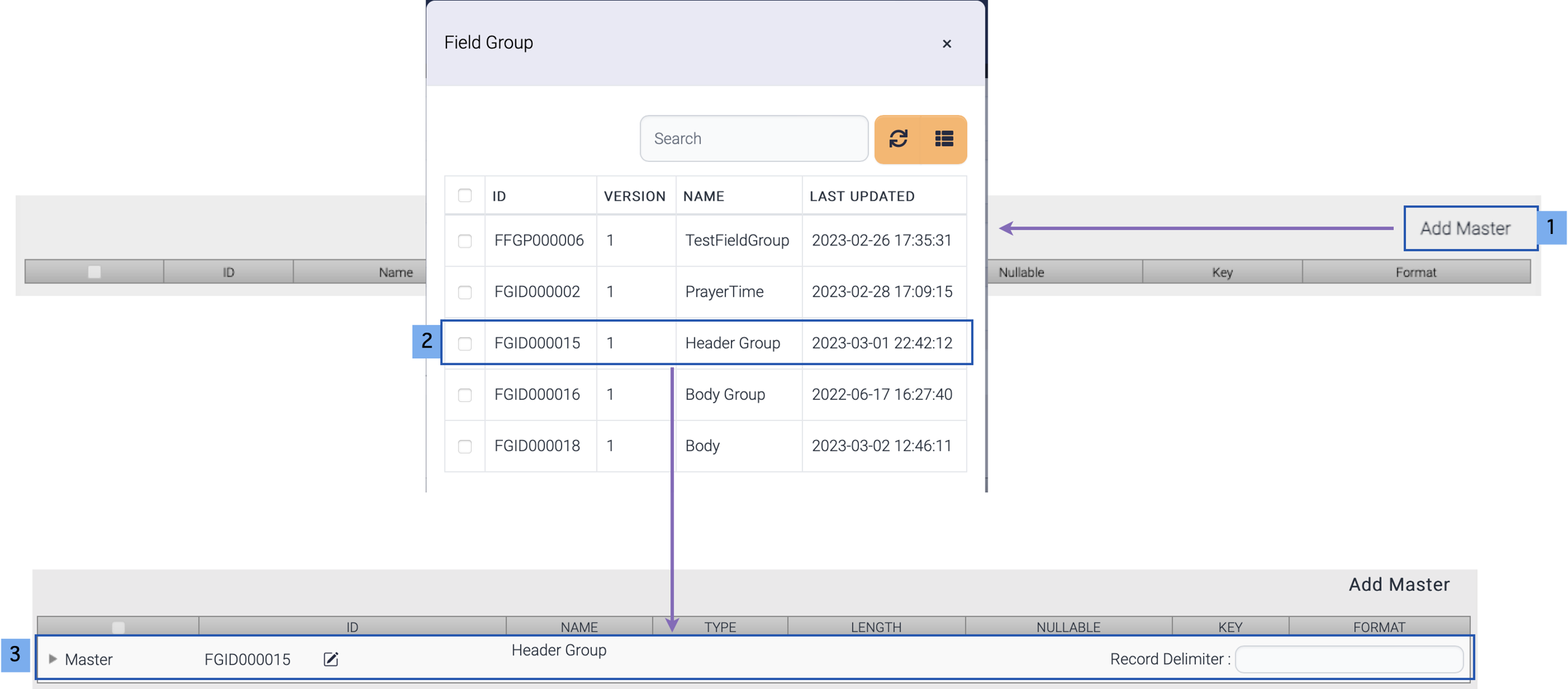
· Add master field group
1) Click Add Master button.
2) Double click a field group.
3) Selected field group is added as a master.
· Add detail field group.
1) Click Add Detail button.
2) Double click a field group.
3) Selected field group is added as detail field group.
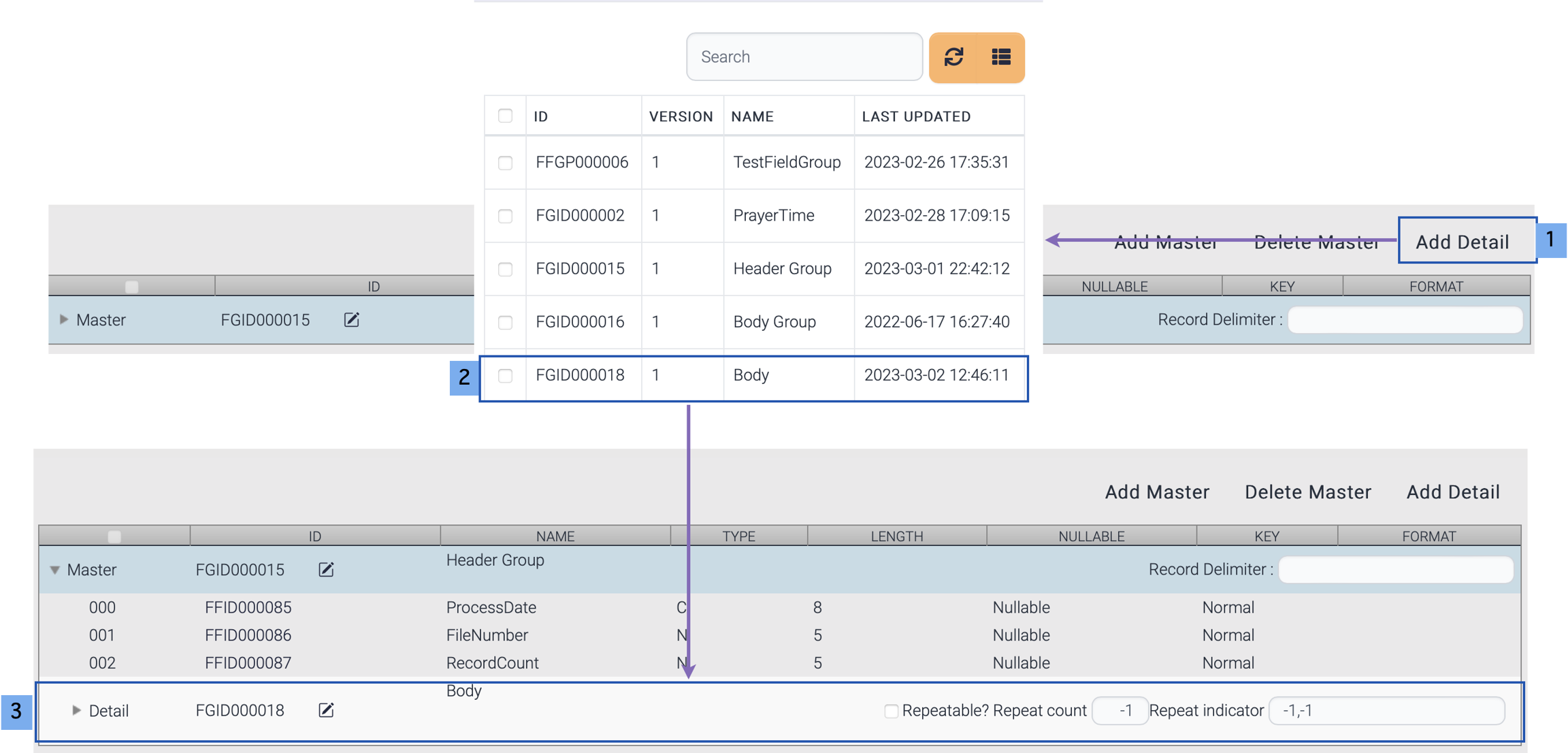
If this detail group is repeated, set the repeat count or indicator.
If any record delimiter is used, set the record delimiter. If no record delimiter is set, master records are separated by length.
DB
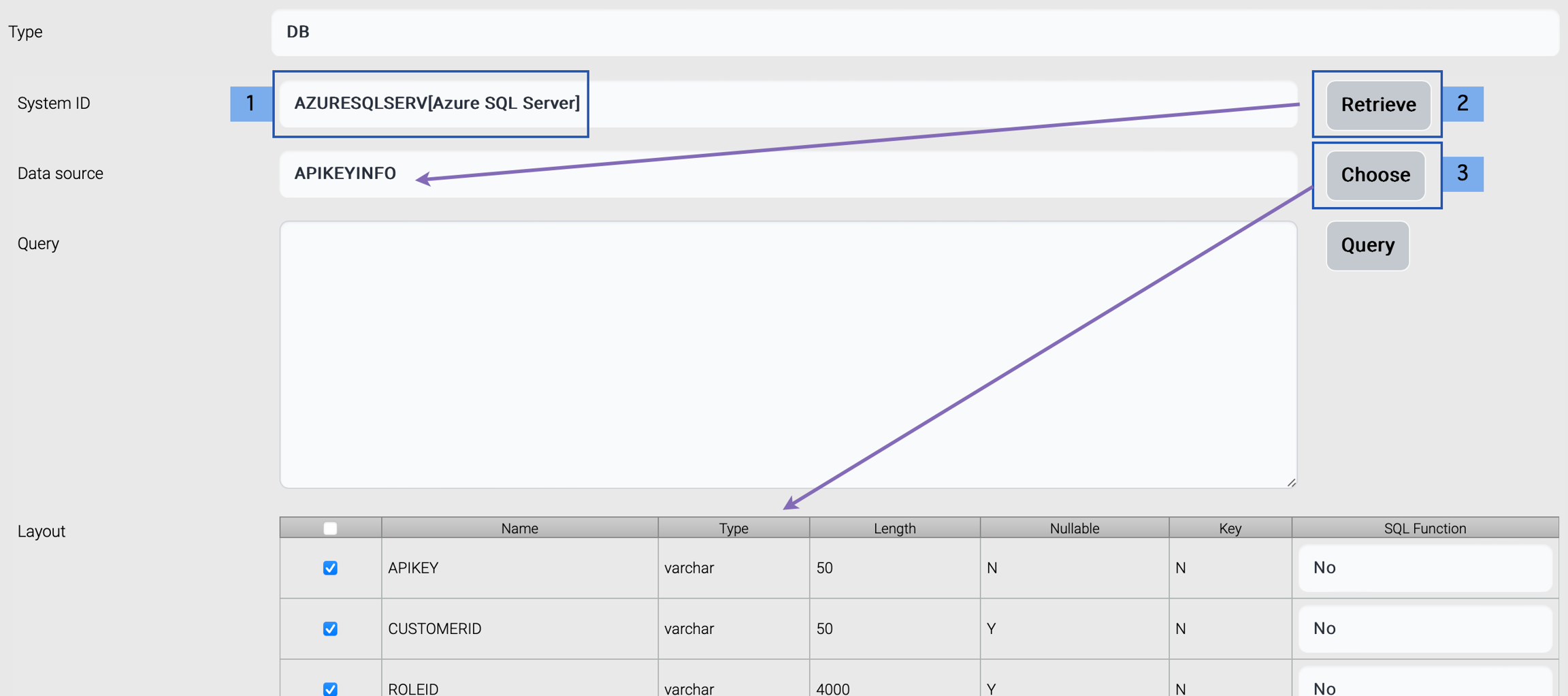
The data structure from database requires system information. The target database should be registered before this step. These are the steps to create a data structure from database.
1) Choose the target database.
2) Click Retrieve button to load tables.
3) Select the target table and click Choose.
Then the fields are displayed.
Or these fields can be generated from a query.
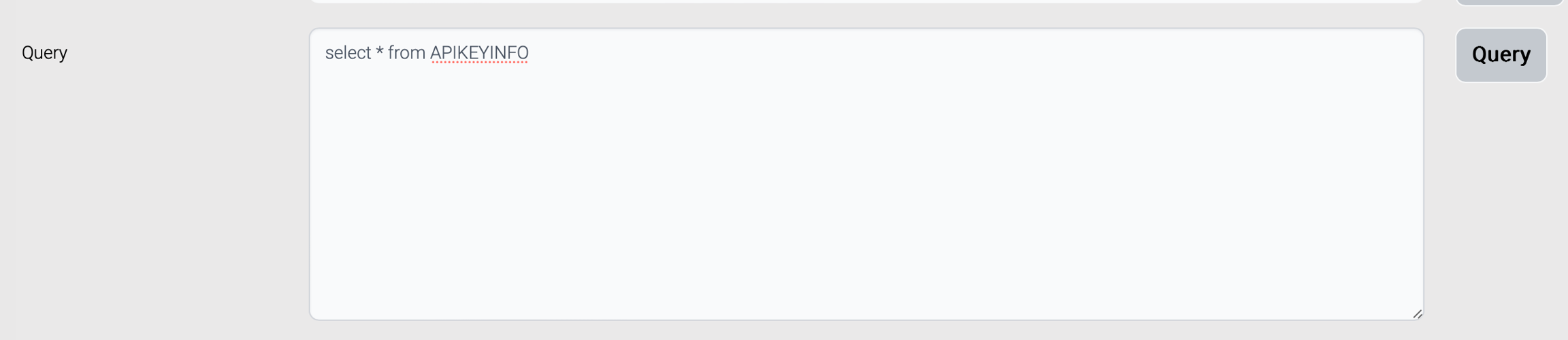
The generated data structure is the same as ISM data structure. This data structure has one master field group.
Excel
The data structure from an excel file comes from a sheet. The excel sheet can be a template excel sheet or just records with column names.
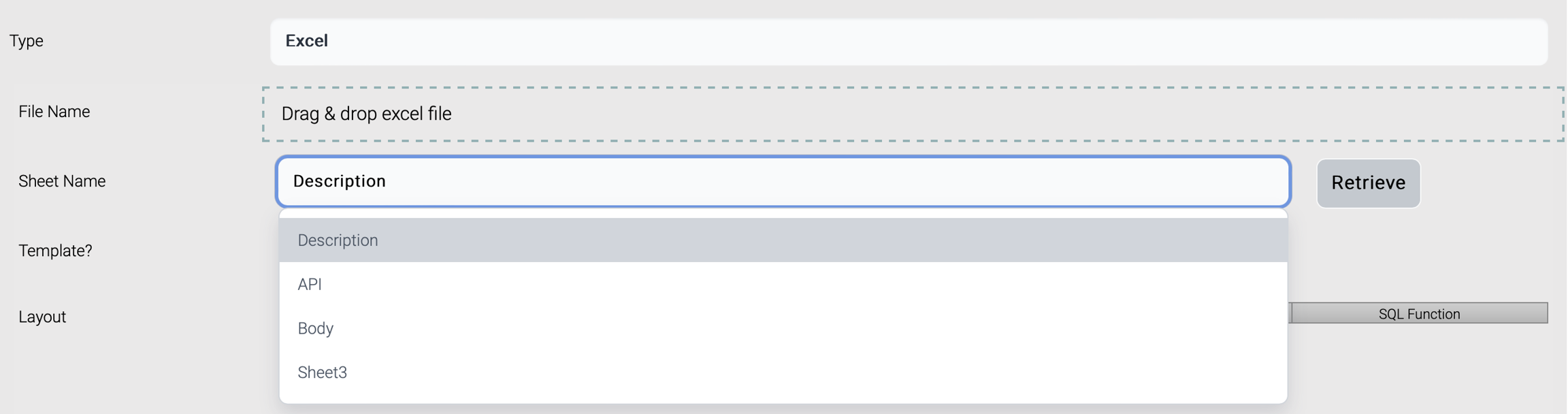
Drag and drop excel file and sheets are listed. Choose the target sheet, check/uncheck Template, and click Retrieve.

Template
Template excel sheet looks like this screenshot. The sample template file(fieldgroup_meta.xls) is located under data directory.

These are the attributes of the template sheet.
FIDLE ID
Field ID to use. Automatically generated
not allowed
Field Name
real field name : table column, message field
mandatory
Field Description
Field description
optional
Type
Field type
mandatory
C - Char
N - Number
D - Date
B - Binary
Length
Field length. If length is not fixed, just enter 0
mandatory
only number for binary type, only 4 is allowed
format
Field format. Used for Number and Date for Number, use NNNN.NN. The dot means a point. This point is included in the field length. for Date, use java date format
optional mandatory for date
fill letter
this letter is used to fill remaining bytes, when the field is used for fixed length data For Number type default fill letter is 0. For char type default fill letter is ' '
optional
one byte letter.
alignment
alignment type - left, right. For char type, left alighment is defult. For number type, right alignment is default.
optional
L - left R - right
length field type
indicates this field shows the length of partial or entire data
optional
T - whole length
P - partial length
F - field group length
N - not a length field
adjustment value
Used when this field is length field which shows partial or entire length of message. If the length shows the entire length, adjustment value is 0. But when this value doesn't include all the fields in the field group or entire message, the correct length should be adjusted by this adjustment value. Add the adjustment value after calculating the length value. for example, length value is 100 and adjustment value is 8. Result length value is 108. length value is 100 and adjustment value is -8. Result length value is 92.
optional
> 0 = 0 < 0
is key
it shows this field is key field or not several key fields are allowed for one field group
optional
Y = Key field N = Normal field
nullable
used when this field stands for table column. If the input value is null, and nullable is true, then null data is inserted into table. Default value is nullable
optional
Y = Nullable N = Not null
is sql function
Used after transformation for table operation. If sql function flag is true, the result value of the transformation of this field is treated as a sql function and generated sql query contains the result as a part of the query, not the variable.
optional
Y = SQL Function N = normal field
inout type
for stored procedure default is input
optional
I = IN O = OUT B = INOUT
Data
If the sheet is not a template, the first row is treated as header, parsed, and displayed. It is not necessary for the header to start from the first row of the sheet. The first row mean the first row which has data.


XML
This type of data structure is generated from a sample xml. Enter a sample xml, click Parse button, and the parsed result is displayed at the bottom.
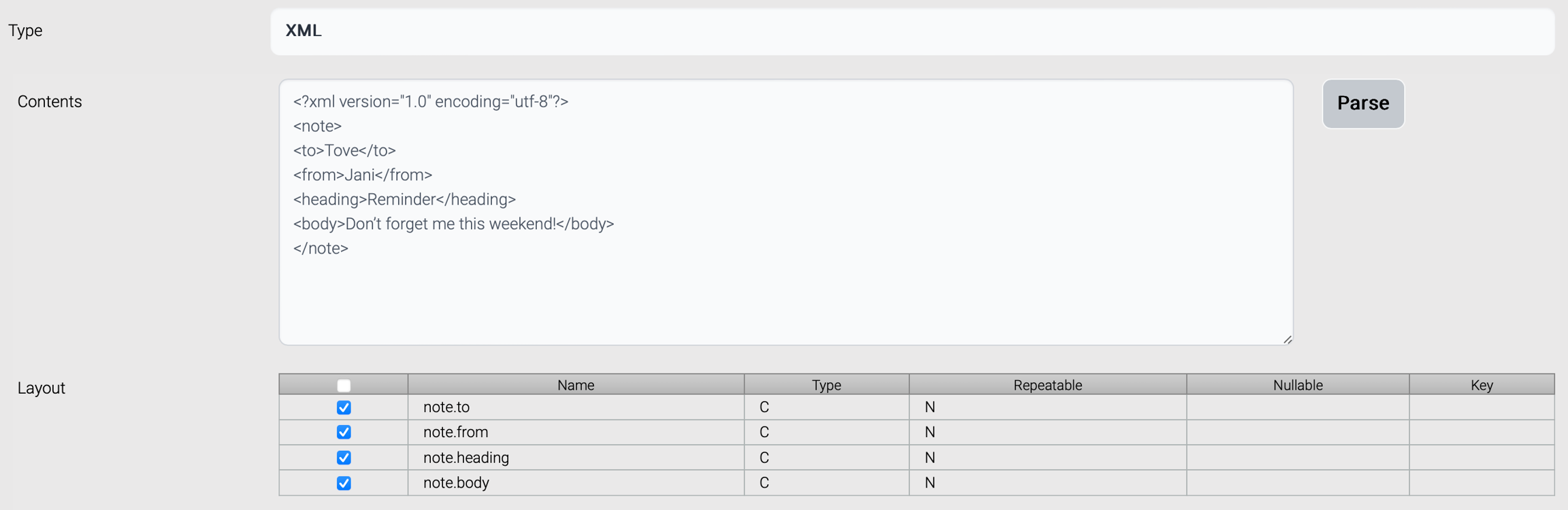
If an element is repeatable, set repeated attribute to the repeatable element.
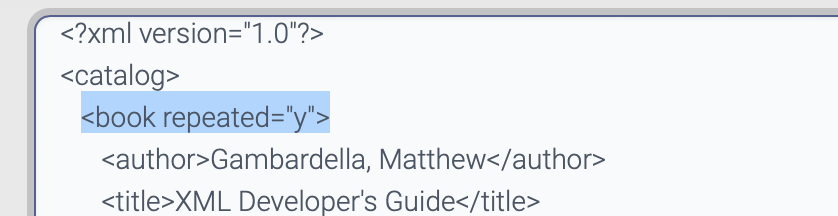
The elements in the sample xml should contain dummy data. If the xml has empty element like this:
<?xml version=-1.0- encoding="utf-8-">
<doc>
-
<dummy>1</dummy>
<empty1></empty1>
<empty2/>
</doc>
<empty1> and <empty2> elements are ignored during the parsing.
If the sample xml is copied from an editor like Microsoft Word, xml parsing may fail. The single quotation('') and double quotation("") are not same as the text editor.
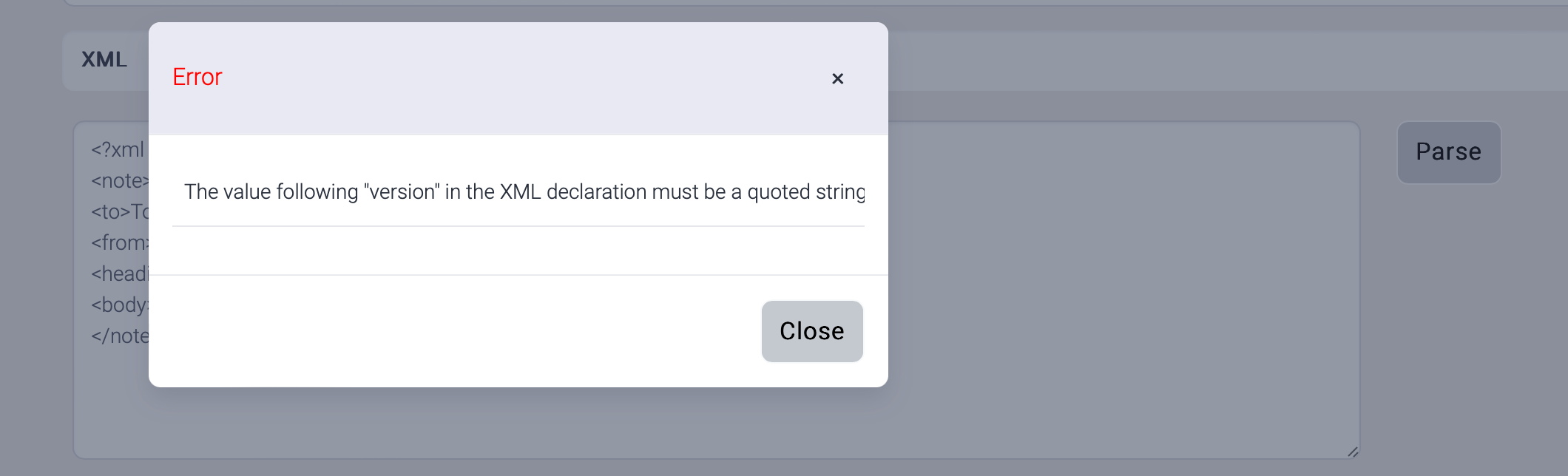
Quotation from MS Word - ![]()
Quotation from text editor - ![]()
There is a limit on XML data structure. Current XML data structure cannot handle the attributes of an element.
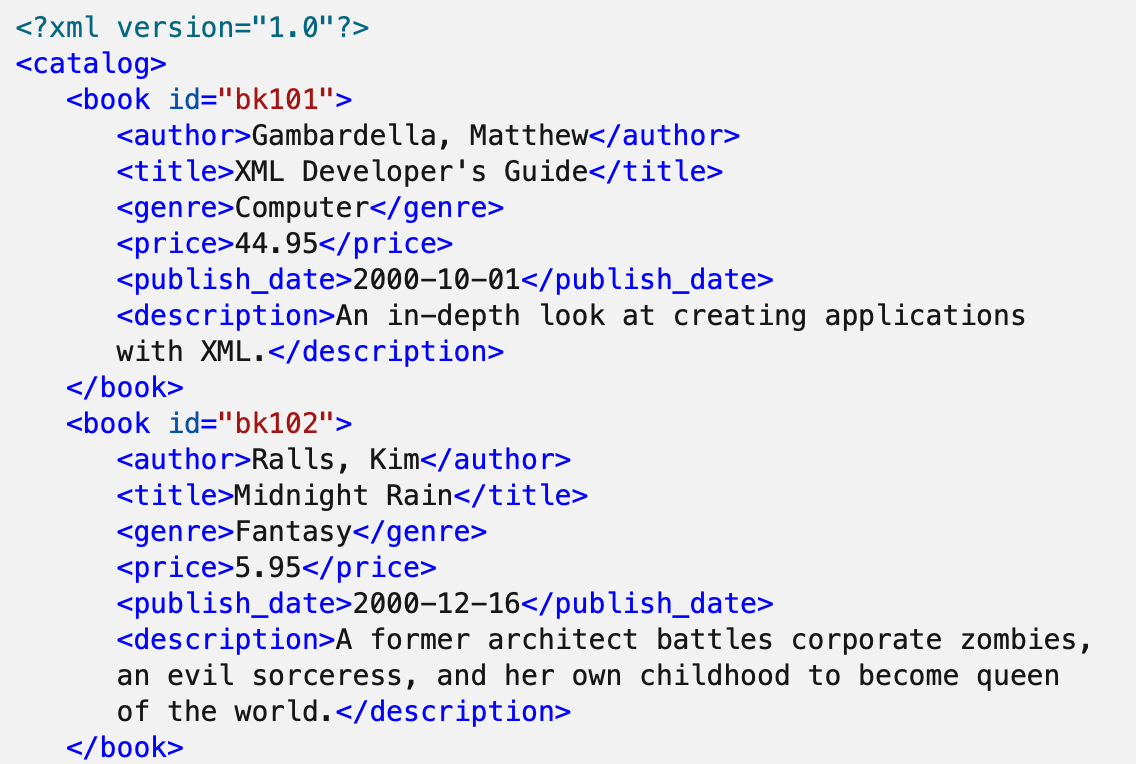
The <book> element above xml has id attribute. But this attribute is ignored and removed at the generated xml.
JSON
This type of data structure is generated from a sample json. Enter a sample json, click Parse button, and the parsed result is displayed at the bottom.
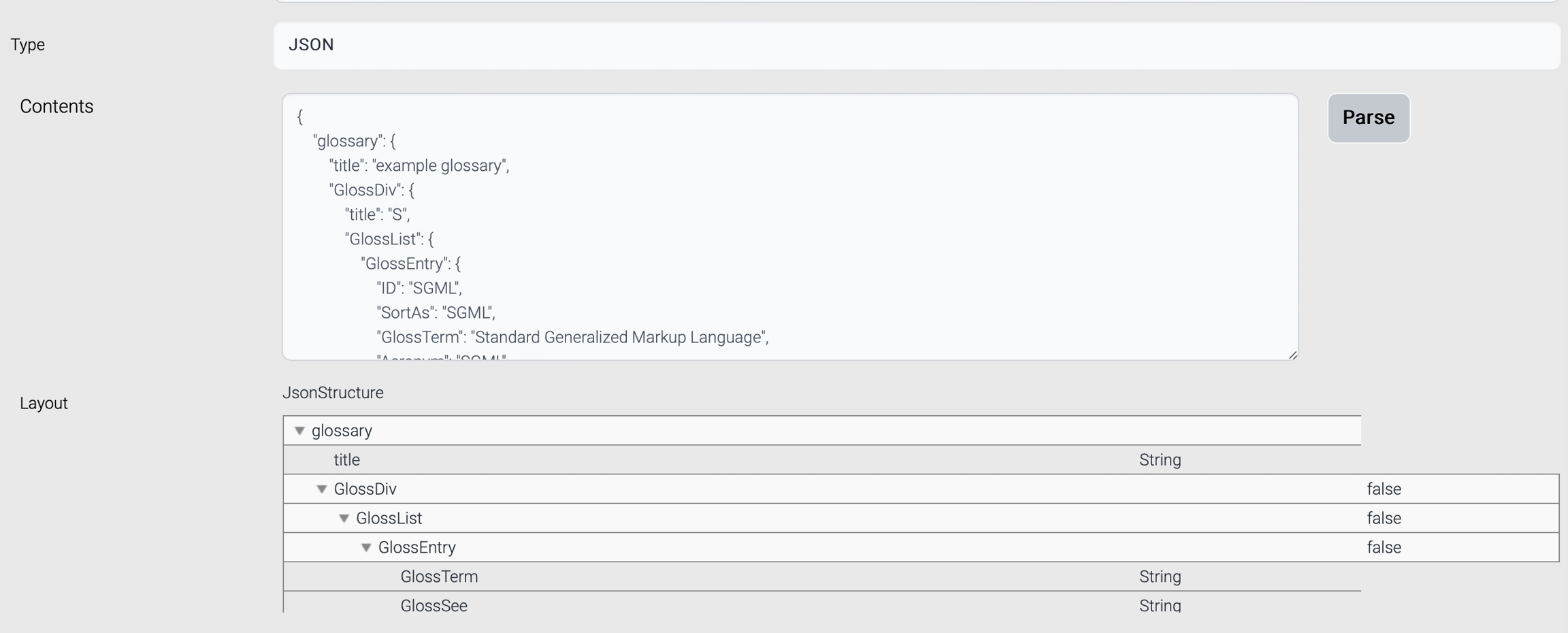
There is a limit on JSON data structure. Current JSON data structure cannot handle primitive(number) and string array type.

GlossSeeAlso field from the above json is not parsed correctly.
WSDL
This type of data structure is generated from WSDL url or file. Enter WSDL url, click Parse button, and the parsed result is displayed at the bottom.
Last updated